Transformer는 간략하게 말하자면 위와 같은 구조를 했더니 번역이 잘 되었다는 논문(Attention All You Need)의 모델명입니다.
왼쪽이 Encoder, 오른쪽이 Decoder 입니다.
Input Embedding Layer를 통해 embedding을 수행하고, Positional Encoding을 통해 문장에 순서 정보를 주입합니다.
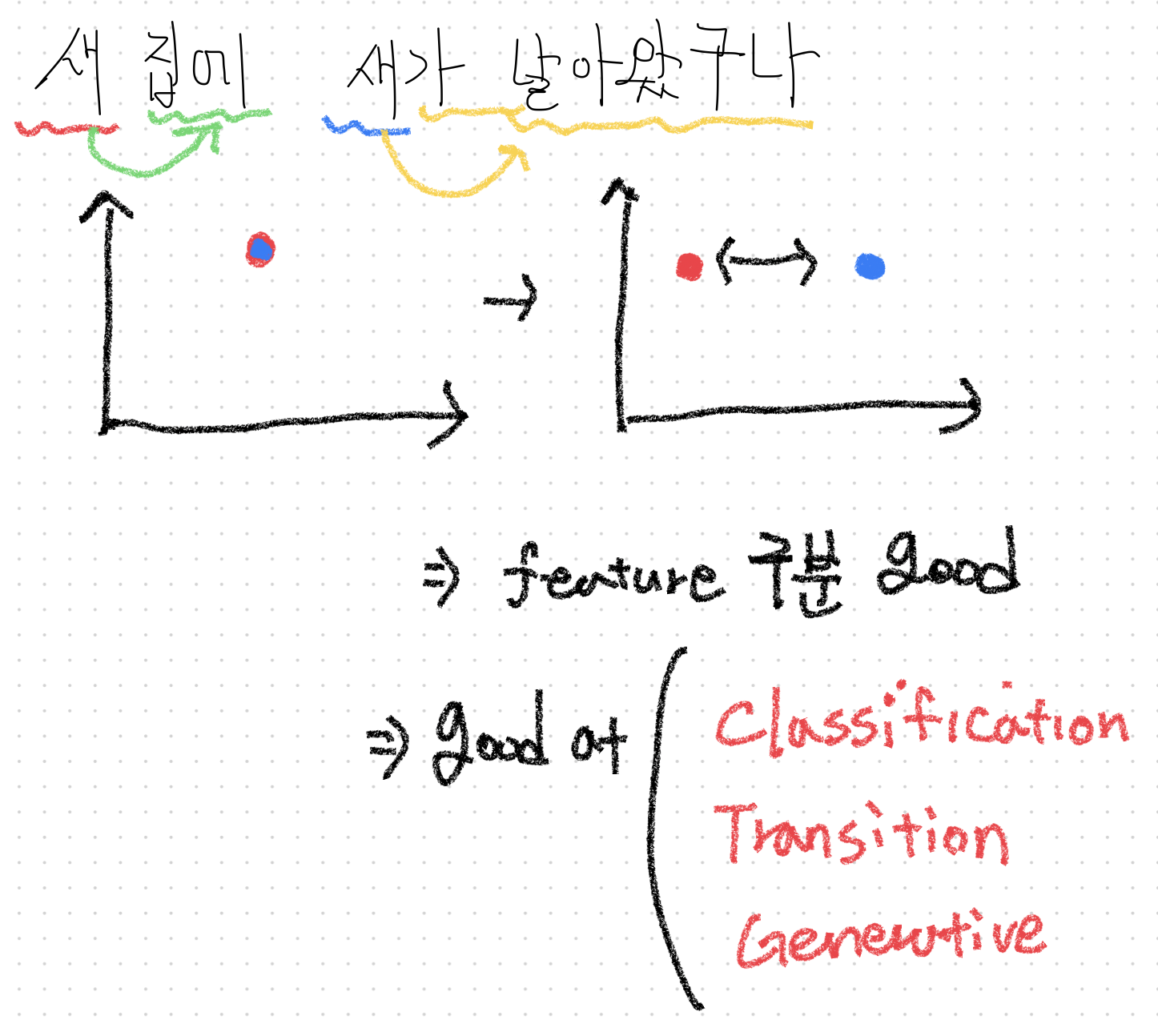
"새 집에 새가 날아왔구나" 라는 문장에서 '새'라는 단어는 임베딩을 수행한 임의의 차원에서 같은 공간에 있을 수 밖에 없습니다. 그 형태가 똑같기 때문입니다.
하지만 우리는 "집에"라는 내용, "~가 날아왔구나"와 같은 내용에 Attention(집중)을 하면서 두 '새'가 다른 의미임을 알아차릴 수 있습니다. Transformer도 Attention이라는 Mechanism으로 처음에 같았던 Embedding을 서로 다른 Embedding으로 아주 잘 나눠주면서 의미가 잘 나뉠 수 있도록 Feature 추출을 잘 수행합니다.
Self Attention
Attention을 수식으로 표현하면 Query와 Key의 행렬곱 이후 Softmax 연산과 Value를 다시 행렬곱을 수행해주는 형태입니다.
먼저, Query, Key, Value는 Linear 연산을 통해 Embedding 되어진 값이 그대로 나뉘어진 형태입니다. Input과 같습니다. 다만 역할을 다르게 부여하기 위해 이 3가지로 나뉩니다.
Query : 이 문장에 대한 각 단어들이 어디에 Attention할지에 대한 질의입니다.
Key : 질의에 대해 응답하는 Tensor 입니다. 각 단어들에 대한 점수를 매기기위한 매칭을 수행하기 위한 것 입니다.
Value : Query와 Key를 통한 각 단어들의 매칭의 점수 결과를 적용하기 위한 Tensor입니다.
Key를 Transpose(전치)시켜서 행렬 곱을하면, 각 단어 Embedding들이 행렬곱 연산을 수행하면서 Score를 만들어냅니다. 각 단어들에 대한 Score를 간단히 정리하기위해 Softmax를 적용합니다.
root(d_k)는 극단적으로 각 단어들끼리 Embedding 값이 차이가 나지 않기 위한 Smoothing 효과를 주기 위함입니다.
Softmax 연산 이후 Value와 행렬곱을 할 경우, 각 score들이 반영되어 각 단어들이 새로운 Embedding vector들을 만들어줍니다.
이것이 자체적으로 Attention해야하는 부분에 대한 정보를 추가하여 New Embedding vector를 만드는 Self Attention 입니다.