Word Embedding
- Word Embedding은 단어 또는 token을 임베딩 벡터로 나타내는 것입니다.
Vectorization
- Vecotirzation은 단어나 token이 컴퓨터와 같은 연산 장치에서 인식하여 처리할 수 있게해줍니다.
- One hot encoding은 많은 Vecorization 방법 중 하나입니다.
- apple [1, 0, 0, ...]
- banna [0, 1, 0, ...]
- 하지만, One hot encoding은 이 두 단어간의 연관성을 담지 못합니다.
- 두 단어는 과일이므로 Vector Space에서 비슷한 Space에 위치해 있어야합니다.
- word2vec, glove, fasttext 등과 같은 방법들이 token을 vectorization 하는데에 더 적합합니다.
Transformer's embedding layer
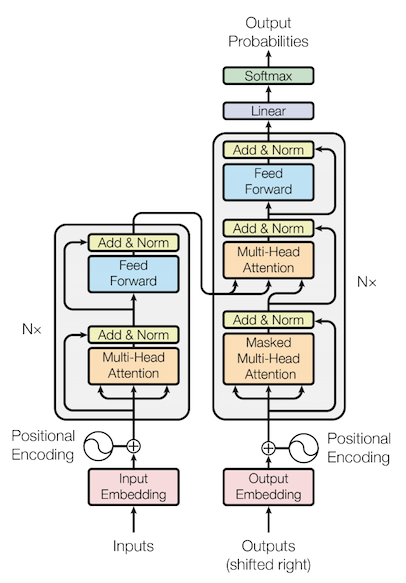 Transformer Structure
Transformer Structure
- Input layer인 embedding layer는 전체적인 Transformer 구조 속에서 token을 적합한 embedding vector로 만들어주도록 학습됩니다.
- 따라서 Word Embedding을 깊게 아는 것 보다는 "Word Embedding이 Token을 Embedding Vector로 나타내주는 기능을 해주는구나"는 기능적인 면을 인지하는 게 좋습니다.
- I -> 40 -> [24,231,45,....]
- love -> 3021 -> [345,461,334,...]
- 위 처럼 단어는 Tokenizer를 통해 id로 표현되고, Token에서 일정 크기의 Embeding vector로 변환 후 Transformer 구조에서 학습이 진행됩니다.
- Input embedding layer는 학습 중에 Loss를 줄이는 방향으로 학습이 될 것입니다.